
News
Education

Seoul National University (SNU)
Sep. 2023 - Present, CSE, Integrated M.S. and Ph.D. (Adviser: Jaesik Park)

Pohang University of Science and Technology (POSTECH)
Feb. 2019 - Feb. 2023, CSE, B.S. (Summa Cum Laude)
Experience

NVIDIA (Spatial Intelligence Lab)
June 2026 - Dec. 2026, Research Scientist Intern / Santa Clara, CA
Exploring video world models with consistent, stateful dynamics

Morpheus AI
Feb. 2026 - May 2026, Research Intern / Remote from Seoul
Worked with Xun Huang and Yicong Hong on stateful video world models while Morpheus AI was in stealth mode (now part of Roblox)

Carnegie Mellon University (Robotics Institute)
Oct. 2025 - Jan. 2026, Visiting Ph.D. Student (Jun-Yan's Lab) / Pittsburgh, PA
Worked with Ruihan Gao, Ava Pun, Wenzhen Yuan, and Jun-Yan Zhu on generative AI for accessibility (Text2TactileGraphics)

Adobe Research
June 2025 - Sep. 2025, Research Scientist Intern / San Francisco, CA
Worked with Xun Huang, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, and Eli Shechtman on building fast and interactive video generative models (MotionStream)
Publications

Text-based Tactile Graphics Generation for the Visually Impaired
Ruihan Gao*, Joonghyuk Shin*, Ava Pun, Jaesik Park, Wenzhen Yuan, Jun-Yan Zhu
ECCV 2026 - [Paper | Project Page | Code | Models | Data | ]
We introduce Text2TactileGraphics, a fabrication-aware generative system that turns natural-language prompts into 3D-printable 2.5D tactile graphics with global geometry, tactile textures, and braille for blind and low-vision users.
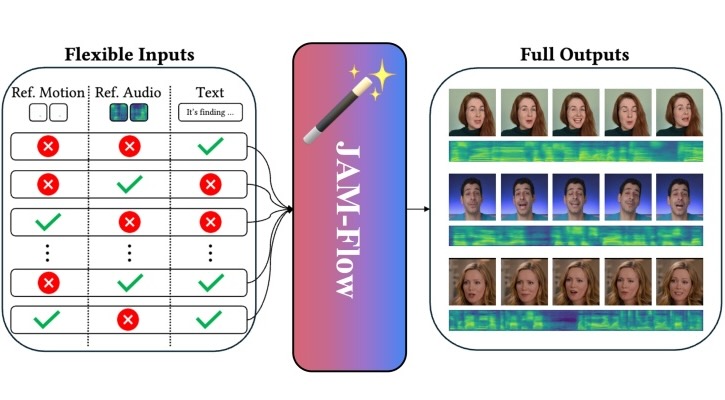
JAM-Flow: Joint Audio-Motion Synthesis with Flow Matching
Mingi Kwon*, Joonghyuk Shin*, Jaeseok Jeong, Jaesik Park†, Youngjung Uh†
ECCV 2026 - [Paper | Project Page | ]
We present a unified framework that jointly generates synchronized facial motion and speech using flow matching and MM-DiT, enabling diverse audio-visual synthesis tasks within a single model.

Direct Reward Fine-Tuning on Poses for Single Image to 3D Human in the Wild
Seunguk Do, Minwoo Huh, Joonghyuk Shin, Jaesik Park
ICLR 2026 - [Paper | Project Page | Code | ]
We introduce DRPOSE, a direct reward fine-tuning method that improves pose accuracy in single-view 3D human reconstruction, especially for dynamic and acrobatic poses, without requiring expensive 3D human assets.
MotionStream: Real-Time Video Generation with Interactive Motion Controls
Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, Jaesik Park, Eli Shechtman, Xun Huang
ICLR 2026 (Oral, 1.13%) - [Paper | Project Page | Post | Code | ]
MotionStream is a streaming (causal, real-time, and long-duration) video generation system with motion controls, operating at ~30 FPS on a single H100 GPU, unlocking new possibilities for interactive content generation.

Exploring Multimodal Diffusion Transformers for Enhanced Prompt-based Image Editing
Joonghyuk Shin, Alchan Hwang, Yujin Kim, Daneul Kim, Jaesik Park
ICCV 2025 - [Paper | Project Page | Code | ]
We perform a systematic analysis of MM-DiT's bidirectional attention mechanism and introduce a robust prompt-based editing method working across diverse MM-DiT models (SD3 series and Flux).

InstantDrag: Improving Interactivity in Drag-based Image Editing
Joonghyuk Shin, Daehyeon Choi, Jaesik Park
SIGGRAPH Asia 2024 - [Paper | Project Page | Code (230+) | ]
We present InstantDrag, an optimization-free pipeline for fast, interactive drag-based image editing that requires only an image and drag instruction as input, learning from real-world video datasets.
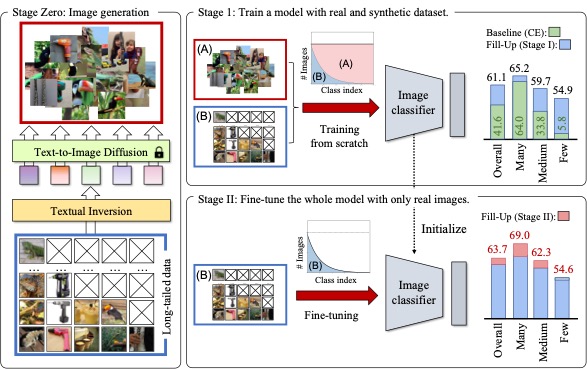
Fill-Up: Balancing Long-Tailed Data with Generative Models
Joonghyuk Shin, Minguk Kang, Jaesik Park
arXiv 2023 - [Paper | Project Page | ]
We propose a two-stage method for long-tailed (LT) recognition using textual-inverted tokens to synthesize images, achieving SOTA results on standard benchmarks when trained from scratch.

StudioGAN: A Taxonomy and Benchmark of GANs for Image Synthesis
Minguk Kang, Joonghyuk Shin, Jaesik Park
TPAMI 2023 - [Paper | Code (3500+) | ]
We present StudioGAN, a comprehensive library for GANs that reproduces over 30 popular models, providing extensive benchmarks and a fair evaluation protocol for image synthesis tasks.
Personal
I am a big fan of baseball. I played for POSTECH baseball team (Tachyons) for 5 years, as a captain and a catcher. I love animals. I live with a dog named Poby. I also like Pokemon, travelling, and FIFA video games.

Last updated on June, 2026 · with Face Looker