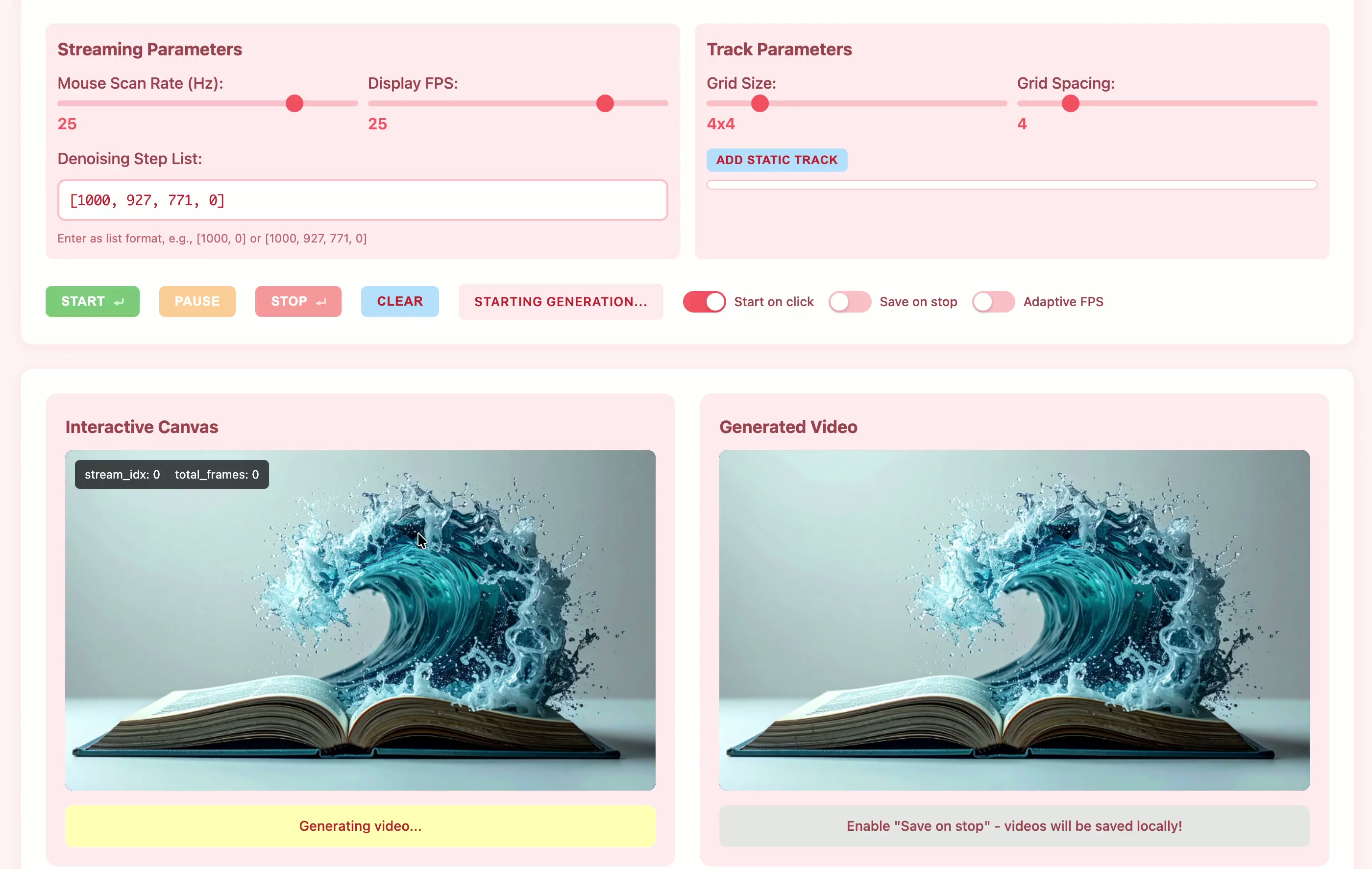
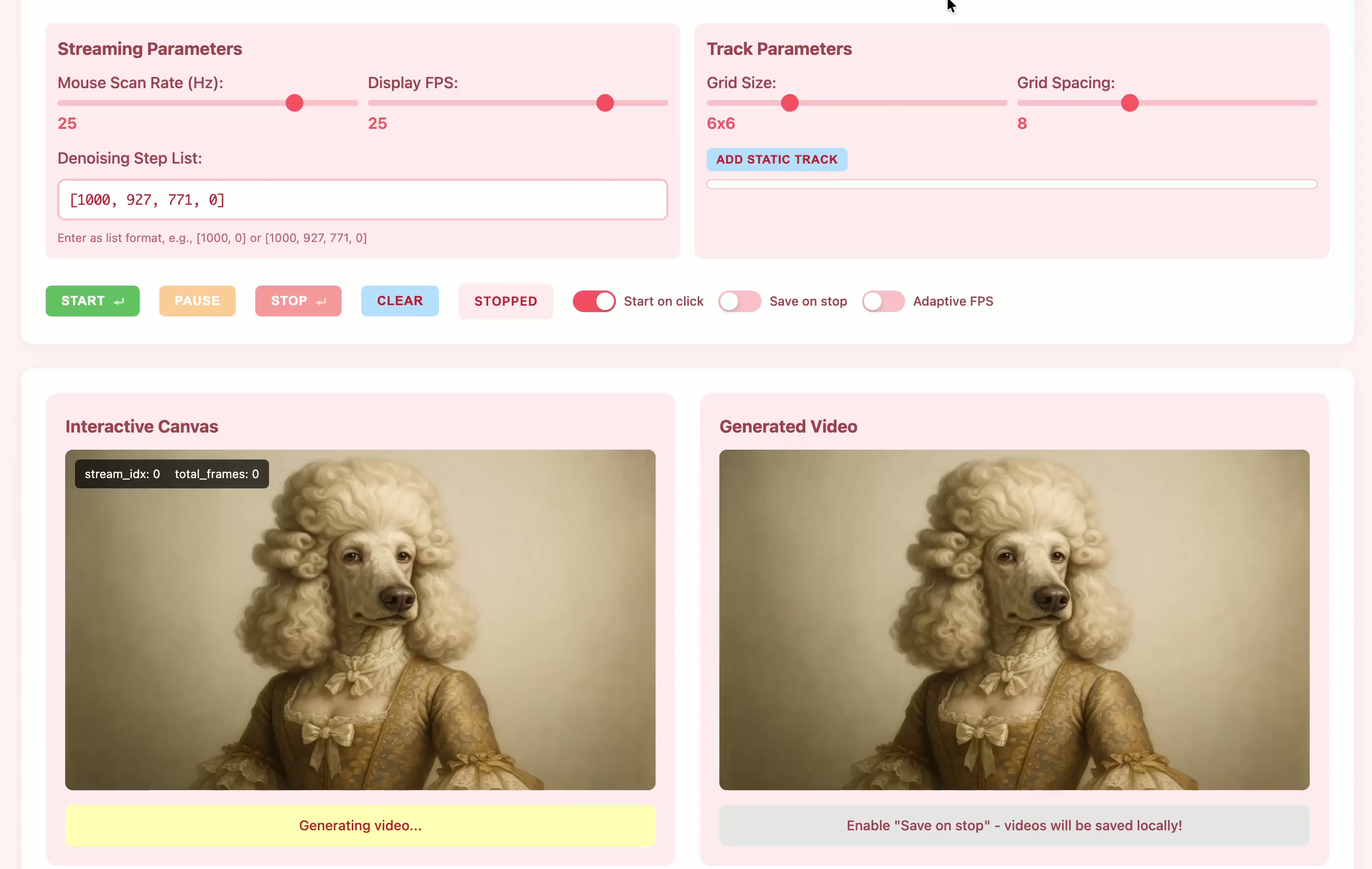
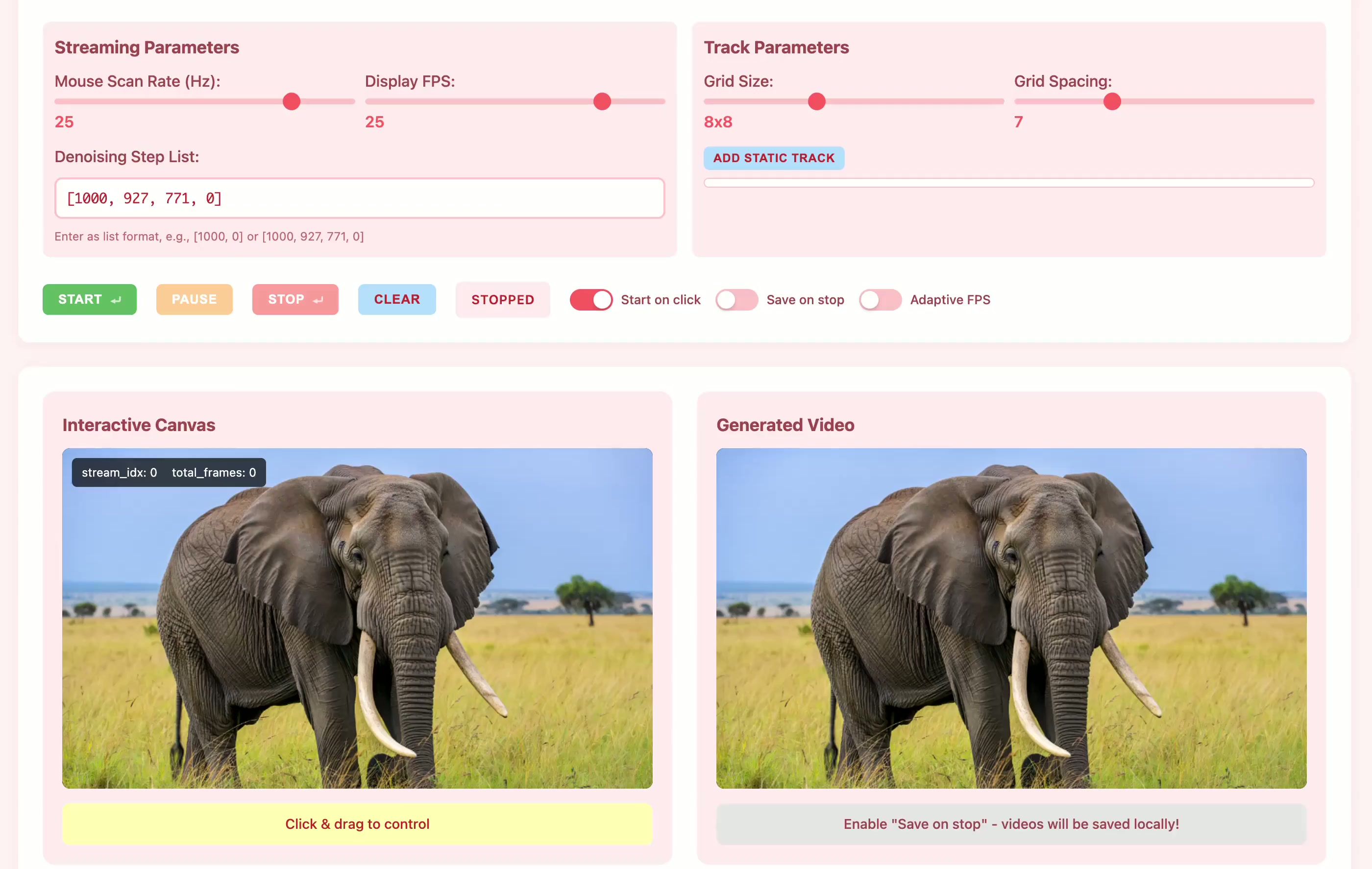
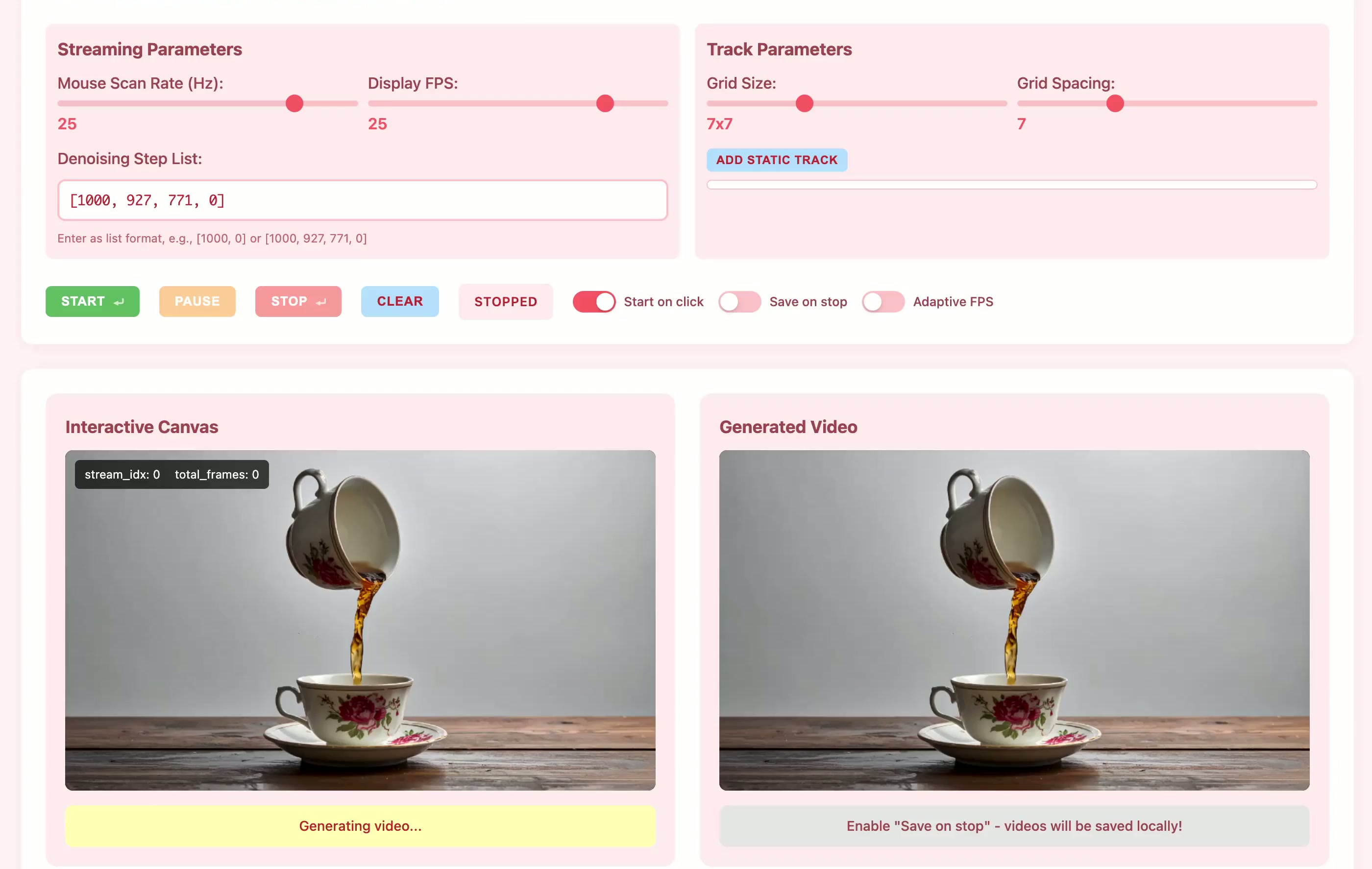
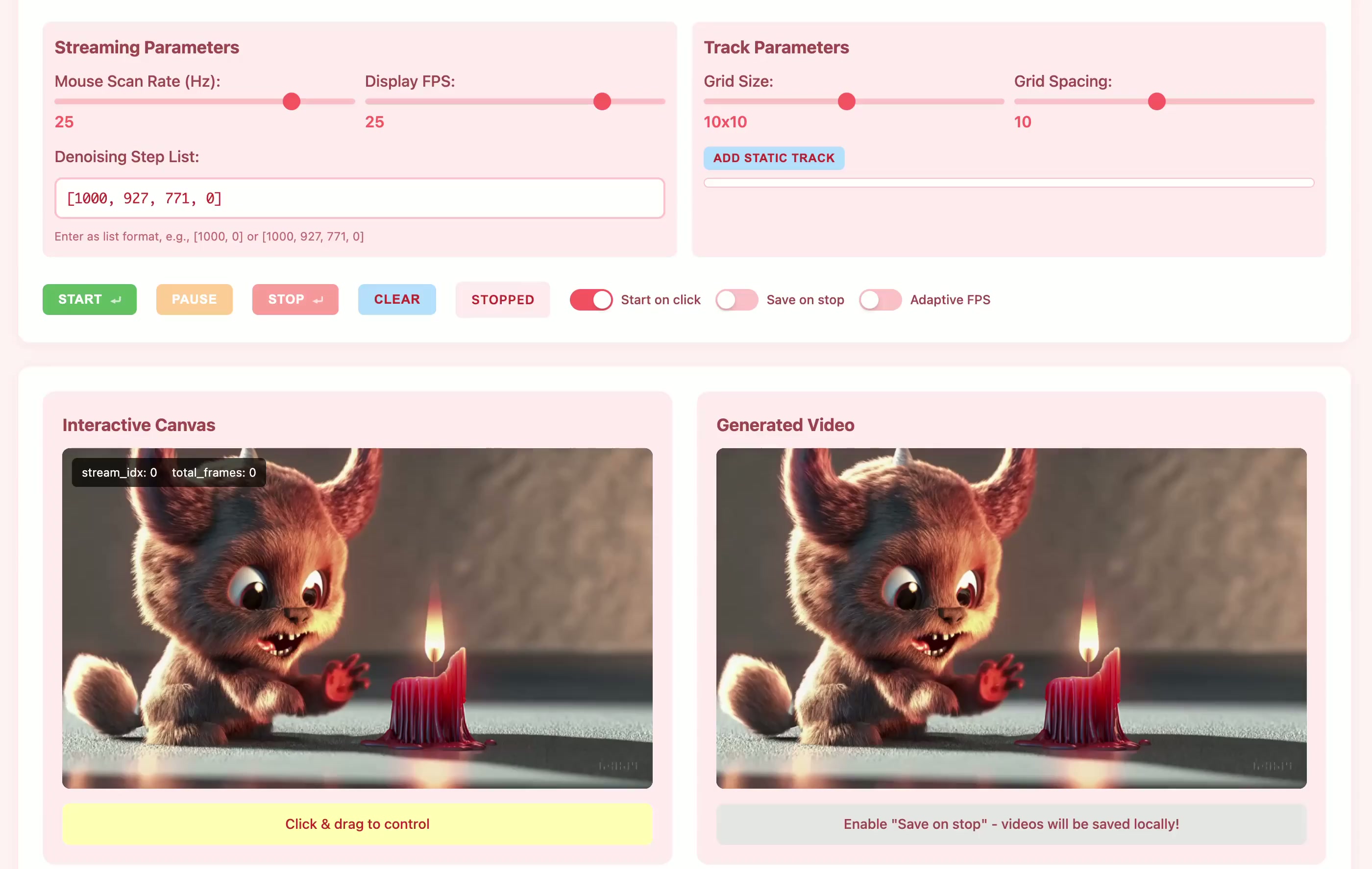
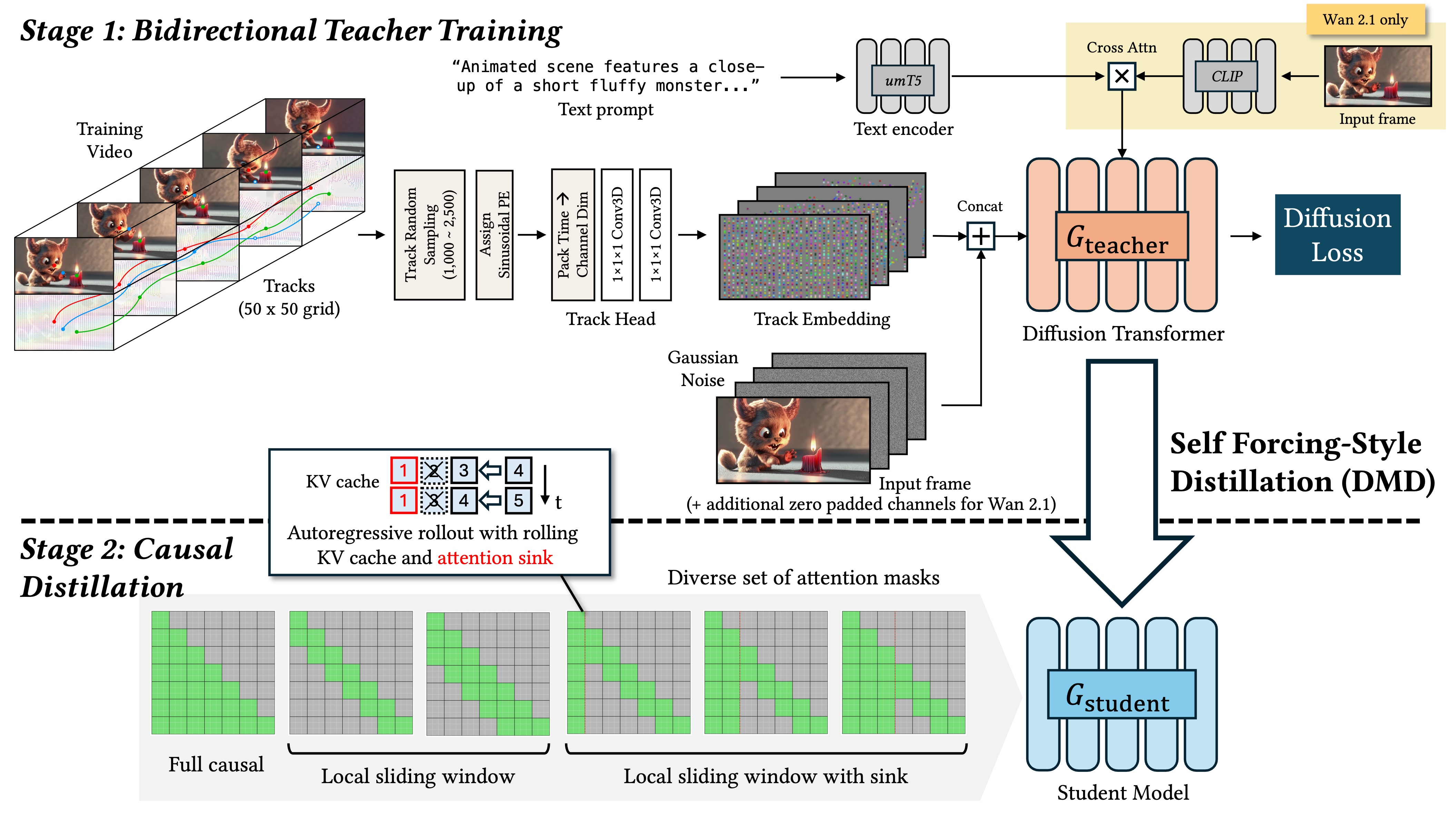
Current motion-conditioned video generation methods suffer from prohibitive latency (minutes per video) and non-causal processing that prevents real-time interaction. We present MotionStream, enabling sub-second latency with up to 29 FPS streaming generation on a single GPU. Our approach begins with augmenting a text-to-video model with motion control, which generates high-quality videos that adhere to the global text prompt and local motion guidance, but does not perform inference on-the-fly. As such, we distill this bidirectional teacher into a causal student through Self Forcing paradigm with distribution matching loss, enabling real-time streaming inference. Several key challenges arise when generating videos of long, potentially infinite time-horizons – (1) bridging the domain gap from training on finite length and extrapolate under infinite-horizon, (2) sustaining high quality, preventing error accumulations, and (3) maintaining fast inference, without incurring growth in computational costs due to increasing context windows. A key to our approach is introducing carefully designed sliding window causal attention with KV cache combined with attention sinks. By incorporating self-rollout with attention sinks and KV cache rolling during training, we properly simulate inference-time extrapolations with a fixed context window, enabling constant-speed generation of arbitrarily long videos. Our models achieve state-of-the-art results in motion following and video quality while being two order magnitude faster, uniquely enabling infinite-length streaming. With MotionStream, users can paint trajectories, control cameras, or transfer motion, and see results unfold in real-time, delivering a truly interactive experience.